##########################################################################################
# If you use this code to analyze data, please cite the following three papers:
# Lin W-Y (2016). Beyond rare-variant association testing: Pinpointing rare causal variants in case-control sequencing study. Scientific Reports, 6: 21824.
# Lin W-Y, Lou XY, Gao G, Liu N (2014). Rare Variant Association Testing by Adaptive Combination of P-values. PLoS ONE, 9: e85728. [PMID: 24454922].
# Cheung YH, Wang G, Leal SM, Wang S (2012). A fast and noise-resilient approach to detect rare-variant associations with deep sequencing data for complex disorders. Genetic epidemiology 2012, 36(7):675-685.
# Any question, please contact: Wan-Yu Lin, linwy@ntu.edu.tw, Institute of Epidemiology and Preventive Medicine, National Taiwan University
# Thank you.
# Acknowledgements: This program was developed based on Cheung et al.'s code. Thank them for sharing their R code.
##########################################################################################
The R code to implement the ADA prioritization method Example file: ADAfile
In R, the code to implement this function is:
source("ADAprioritized.r")
ADATest('ADAfile.txt', 0.05, 1000, FALSE, 'additive', TRUE) # wait for ~3 seconds
where 'ADAfile.txt' is the data file, in which the first column is the disease status (1: case; 0: control), and column 2 to the last column are the numbers of minor alleles.
The following input elements of this function are:
mafThr = 0.05, (Exclude SNPs with combined MAF > 0.05)
num_perm = 1000, (the number of permutations)
midp = FALSE, (P-values according to the Fisher's exact test)
mode = 'additive', (mode of inheritance = "additive")
twoSided = TRUE (two-sided test)
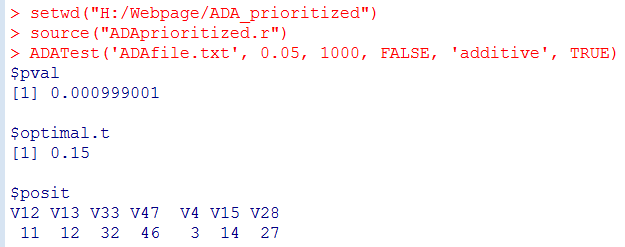
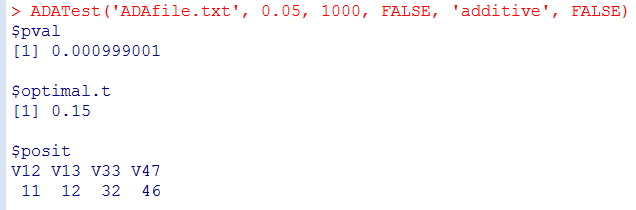
Output: The output contains three objects:
(1) pval: the P-value of the ADA test.
(2) optimal.t: the P-value threshold producing the minimum P-value for the observed (unpermuted) sample.
(3) posit: the variants with per-site P-values smaller than optimal.t. The final set of variants selected by the ADA prioritization method.
If posit returns 32 and 46, it means that No. 32 and No. 46 are important variants. That is, the variants put in the 33rd and the 47th columns in ADAfile.txt are prioritized. Recall that the first column in ADAfile.txt is the disease status.
Using our test sample "ADAfile.txt", you will obtain the following results:
1. With "twoSided = TRUE", both deleterious variants and protective variants are prioritized.
2. The option is changed to "twoSided = FALSE", and so only deleterious variants are prioritized.
Thanks for your interest in our work.
Return to Wan-Yu Lin's homepage